Add or remove data tiers in Elastic Cloud Hosted or Elastic Cloud Enterprise
In Elastic Cloud Hosted and Elastic Cloud Enterprise, you add warm, cold, or frozen capacity from the deployment editor, and you remove a tier only after data can migrate away safely. The default configuration includes a shared tier for hot and content data; that tier is required and cannot be removed.
Review Elasticsearch data tiers so you choose the right tier for your workload.
- On the Create deployment page, click Advanced Settings.
- Click + Add capacity for any data tiers to add.
- Click Create deployment at the bottom of the page to save your changes.

Log in to the Elastic Cloud Console or ECE Cloud UI.
On the home page, find your deployment.
TipIf you have many deployments, you can instead go to the Hosted deployments (Elastic Cloud Hosted) or Deployments (Elastic Cloud Enterprise) page. On that page, you can narrow your deployments by name, ID, or choose from several other filters.
Select Manage.
- From the navigation menu, select Edit.
- Click + Add capacity for any data tiers to add.
- Click Save at the bottom of the page to save your changes.
Follow this section when you need to remove a data tier from an Elastic Cloud Hosted or Elastic Cloud Enterprise deployment. The steps differ depending on whether the tier holds regular indices or searchable snapshot indices (typical for cold or frozen when using index lifecycle management (ILM)).
Disabling a data tier, attempting to scale nodes down in size, reducing availability zones, or reverting an autoscaling change can all result in cluster instability, cluster inaccessibility, and even data corruption or loss in extreme cases.
To avoid this, especially for production environments, and in addition to making configuration changes to your indices and ILM as described in this guide:
- Review the disk size, CPU, JVM memory pressure, and other performance metrics of your deployment before attempting to perform the scaling down action.
- Make sure that you have enough resources and availability zones to handle your workloads after scaling down.
- Check that your deployment hardware profile (for Elastic Cloud Hosted) or deployment template (for Elastic Cloud Enterprise) is correct for your business use case. For example, if you need to scale due to CPU pressure increases and are using a Storage Optimized hardware profile, consider switching to a CPU Optimized configuration instead.
Read https://www.elastic.co/cloud/shared-responsibility for additional details. If in doubt, reach out to Support.
Know whether you are disabling a tier that stores regular indices or searchable snapshots. The frozen tier only holds partially mounted searchable snapshots. The cold tier can hold regular indices or fully mounted searchable snapshots. The hot tier usually holds regular indices, but an ILM policy can mount a fully mounted searchable snapshot on the hot tier (for example, when the searchable_snapshot action runs in the
hotphase). Use these requests to check for searchable snapshot indices on the tier you are removing:# cold data tier: {{search-snap}} indices GET /_cat/indices/restored-* # frozen data tier: {{search-snap}} indices GET /_cat/indices/partial-*To learn more about ILM or shard allocation filtering, see Create your index lifecycle policy, Managing the index lifecycle, and Shard allocation filters.
The frozen tier only stores partially mounted searchable snapshots. Fully mounted searchable snapshots can be allocated to the hot or cold tier depending on the ILM phase, while the cold tier can also hold regular indices. Use the checks in Before you remove a data tier if you are unsure what is on the tier.
When you update the deployment, Elastic Cloud Hosted and Elastic Cloud Enterprise try to move all data from the nodes that are removed. To disable a tier that holds only regular indices, make sure that all data on that tier can be re-allocated by reconfiguring the relevant shard allocation filters. You’ll also need to temporarily stop your ILM policies to prevent new indices from being moved to the data tier you want to disable.
To make sure that all data can be migrated from the data tier you want to disable, follow these steps:
Determine which nodes will be removed from the cluster.
Log in to the Elastic Cloud Console.
From the Hosted deployments page, select your deployment.
On the Hosted deployments page you can narrow your deployments by name, ID, or choose from several other filters. To customize your view, use a combination of filters, or change the format from a grid to a list.
Filter the list of instances by the Data tier you want to disable.
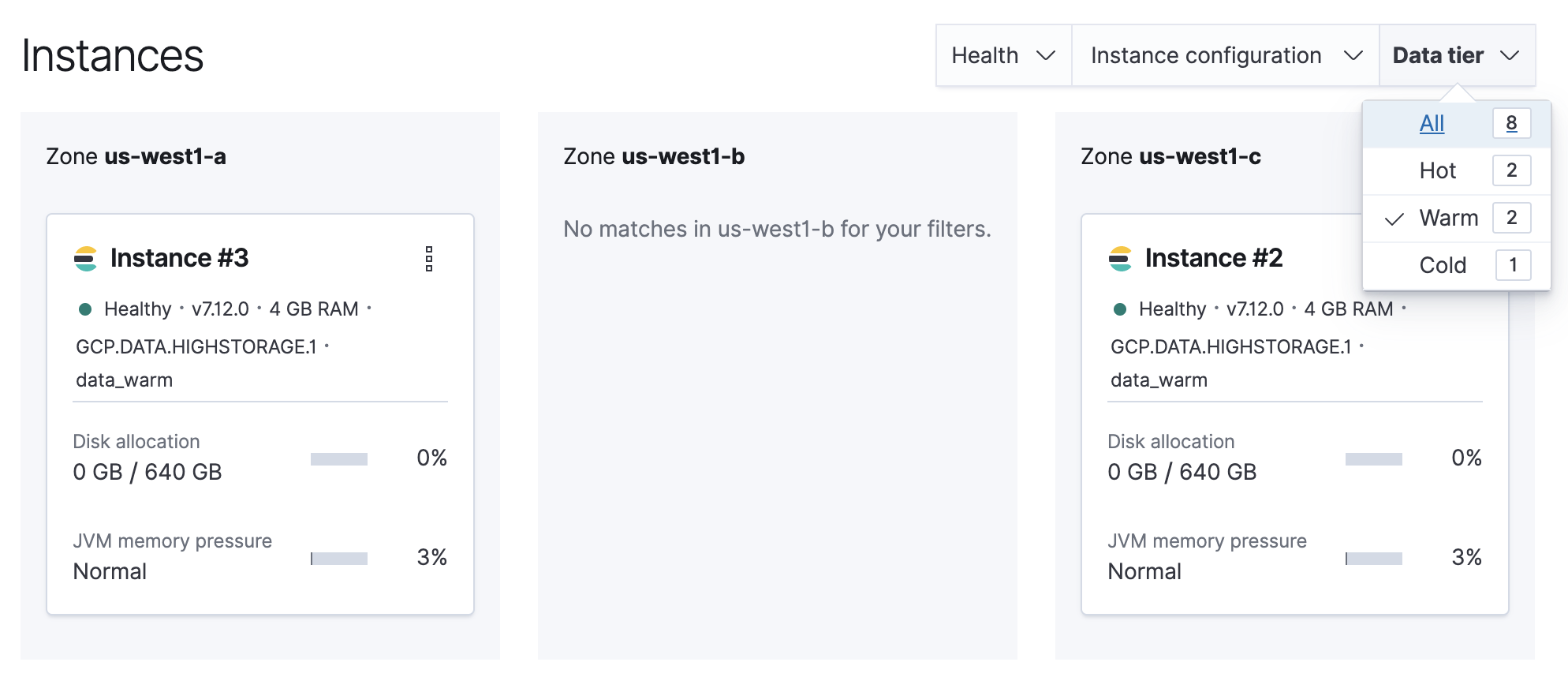
Note the listed instance IDs. In this example, it would be Instance 2 and Instance 3.
From the Deployments page, select your deployment.
Narrow the list by name, ID, or choose from several other filters. To further define the list, use a combination of filters.
Filter the list of instances by the Data tier you want to disable.
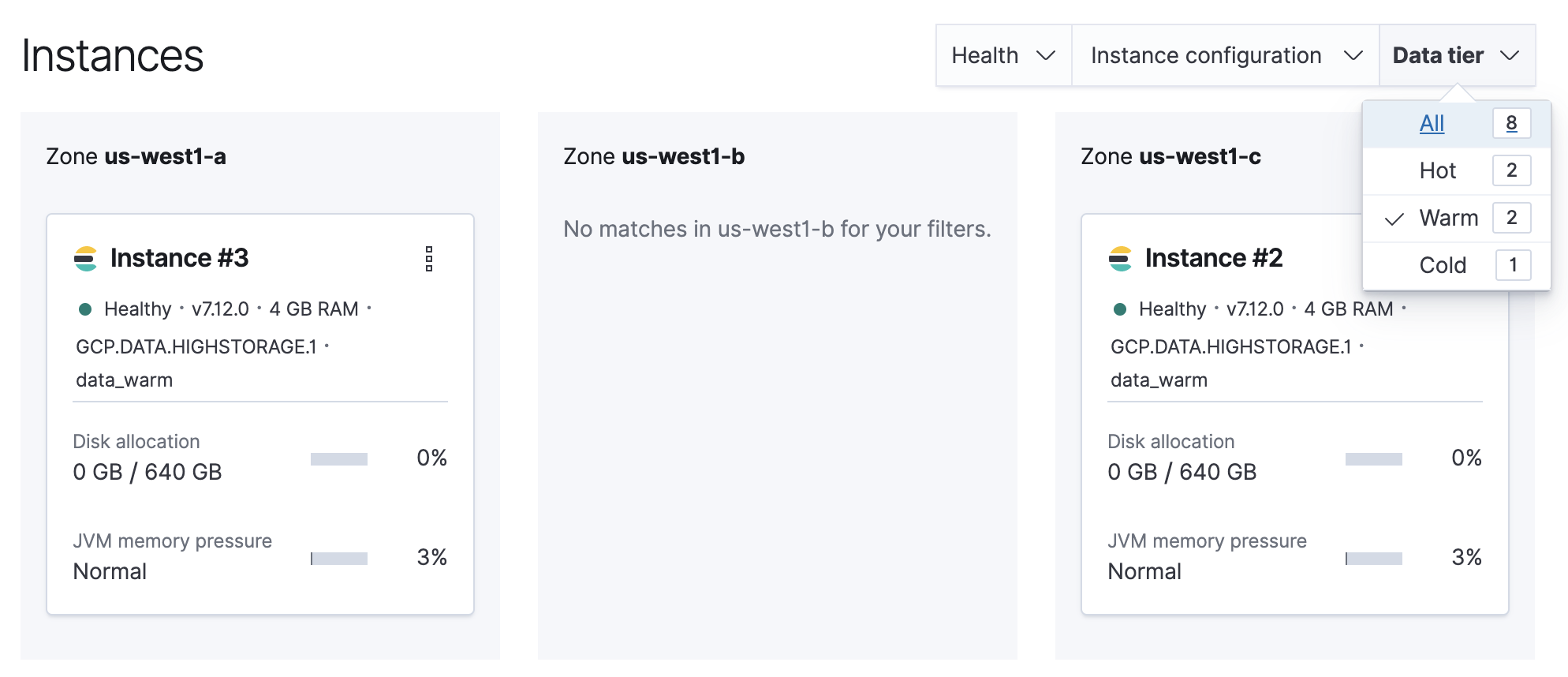
Note the listed instance IDs. In this example, it would be Instance 2 and Instance 3.
Stop ILM.
POST /_ilm/stopDetermine which shards need to be moved.
GET /_cat/shardsParse the output, looking for shards allocated to the nodes to be removed from the cluster.
Instance #2is shown asinstance-0000000002in the output.
Move shards off the nodes to be removed from the cluster.
You must remove any index-level shard allocation filters from the indices on the nodes to be removed. ILM uses different rules depending on the policy and version of Elasticsearch. Check the index settings to determine which rule to use:
GET /my-index/_settingsUpdating data tier based allocation inclusion rules.
Data tier based ILM policies use
index.routing.allocation.includeto allocate shards to the appropriate tier. The indices that use this method have index routing settings similar to the following example:{ ... "routing": { "allocation": { "include": { "_tier_preference": "data_warm,data_hot" } } } ... }You must remove the relevant tier from the inclusion rules. For example, to disable the warm tier, remove the
data_warmparameter and set_tier_preferenceto a tier you are keeping. Prefer promoting data through the lifecycle, for example from warm to cold, not back to hot, unless the cluster has no colder tier to accept the data:PUT /my-index/_settings { "routing": { "allocation": { "include": { "_tier_preference": "data_cold,data_warm,data_hot" } } } }- If the cluster has no cold tier, use the lowest remaining tier in order of preference, for example
data_hotwhen nodata_coldnodes exist. The frozen tier is for partially mounted searchable snapshots only, not a destination for regular indices in this flow.
Updating allocation inclusion rules will trigger a shard re-allocation, moving the shards from the nodes to be removed.
- If the cluster has no cold tier, use the lowest remaining tier in order of preference, for example
Updating node attribute allocation requirement rules.
Node attribute based ILM policies use
index.routing.allocation.requireto allocate shards to the appropriate nodes. The indices that use this method have index routing settings that are similar to the following example:{ ... "routing": { "allocation": { "require": { "data": "warm" } } } ... }You must either remove or redefine the routing requirements. To remove the attribute requirements, use the following code:
PUT /my-index/_settings { "routing": { "allocation": { "require": { "data": null } } } }Removing required attributes does not trigger a shard reallocation. These shards are moved when applying the plan to disable the data tier. Alternatively, you can use the cluster re-route API to manually re-allocate the shards before removing the nodes, or set
requireto migrate shards to a desired tier. For example, to force an index to nodes withdataattribute ofcold, use the following request:PUT /my-index/_settings { "routing": { "allocation": { "require": { "data": "cold" } } } }Adjust the
datavalue to match the custom node attributes and index-level shard allocation filters your indices already use. You cannot send regular indices to the frozen tier.Removing custom allocation rules.
If indices on nodes to be removed have shard allocation rules of other forms, they must be removed as shown in the following example:
PUT /my-index/_settings { "routing": { "allocation": { "require": null, "include": null, "exclude": null } } }
ImportantConfirm that no shards are left on the nodes to be removed after the allocation completes:
GET /_cat/shards(filter bynodeas needed) should show that the tier is empty. Updating settings starts the relocation process, but you must wait until shard allocation and recovery finish. If shards stay on the original tier, use the cluster allocation explain API to determine the cause. Common reasons can be disk watermarks orindex.routing.allocation.total_shards_per_nodeon the destination nodes.Edit the deployment, disabling the data tier.
If autoscaling is enabled, set the maximum size to 0 for the data tier to ensure autoscaling does not re-enable the data tier.
Any remaining shards on the tier being disabled are re-allocated across the remaining cluster nodes while applying the plan to disable the data tier. Monitor shard allocation during the data migration phase to ensure all allocation rules have been correctly updated. If the plan fails to migrate data away from the data tier, then re-examine the allocation rules for the indices remaining on that data tier.
Once the plan change completes, confirm that there are no remaining nodes associated with the disabled tier and that
GET _cluster/healthreportsgreen. If this is the case, re-enable ILM.POST _ilm/start
Fully mounted searchable snapshots on the hot or cold tier can often be moved to another remaining tier by updating the index.routing.allocation.include._tier_preference setting and related allocation rules alone, without a POST _snapshot/.../_restore call. When Elasticsearch creates them with the searchable_snapshot ILM action, the index name is typically prefixed with restored-*. If you mount a snapshot yourself, the index name is not limited to that pattern. Use a full restore to a new regular index when you are rehydrating or when you have partially mounted indices on frozen and need a regular index on another tier. In a frozen tier, the ILM action typically uses a partial-* name prefix; self-managed partial mounts do not have to follow it.
When an ILM policy’s searchable_snapshot action runs in a hot, cold, or frozen phase, it can convert a managed index into a searchable snapshot (restored-* in non-frozen phases, or partial-* in the frozen phase). If the data is no longer required, the delete phase of the same policy can remove it. If you must retain the data while removing the tier, follow these steps:
Stop ILM and check ILM status is
STOPPEDto prevent data from migrating to the phase you intend to disable while you are working through the next steps.# stop {{ilm-init}} POST _ilm/stop # check status GET _ilm/statusCapture a comprehensive list of index and searchable snapshot names, and which snapshot repository each snapshot lives in.
The index name of the searchable snapshots may differ based on the data tier. If you intend to disable the cold tier, use the
restored-*prefix. If the frozen tier is the one to be disabled, use thepartial-*prefix. If you are removing a tier that had a searchable_snapshot action in an earlier phase, for example during thehotphase, also run the same query forrestored-*on that tier.GET <searchable-snapshot-index-prefix>/_settings?filter_path=**.index.store.snapshot.snapshot_name&expand_wildcards=allIn the example we have a list of 4 indices, which need to be moved away from the frozen tier.

(Optional) Save the list of index and snapshot names in a text file, so you can access it throughout the rest of the process.
Remove the aliases that were applied to searchable snapshots indices. Use the index prefix from step 2.
POST _aliases { "actions": [ { "remove": { "index": "<searchable-snapshot-index-prefix>-<index_name>", "alias": "<index_name>" } } ] }NoteIf you use data stream, you can skip this step.
In the example we are removing the alias for the
frozen-index-1index.
Restore indices from the searchable snapshots.
Follow the steps to specify the data tier based allocation inclusion rules for the tier you are keeping.
Remove the associated ILM policy (set it to
null). If you want to apply a different ILM policy, follow the steps to Switch lifecycle policies.If needed, specify the alias for rollover, otherwise set it to
null.Optionally, specify the desired number of replica shards.
POST _snapshot/<snapshot_repository_name>/<searchable_snapshot_name>/_restore { "indices": "*", "index_settings": { "index.routing.allocation.include._tier_preference": "<data_tiers>", "index.number_of_replicas": 0, "index.lifecycle.name": "<new-policy-name>", "index.lifecycle.rollover_alias": "<alias-for-rollover>" } }For
<searchable_snapshot_name>use the names that you obtained in step 2. Adjustindex.number_of_replicasto match your resiliency needs.The example request restores
frozen-index-1and places it in the warm tier; the snapshot can be found infound-snapshots, which is the default snapshot repository.
Repeat steps 4 and 5 until all snapshots are restored to regular indices.
Once all snapshots are restored, use
GET _cat/indices/<index-pattern>?v=trueto check that the restored indices aregreenand are correctly reflecting the expecteddocandstore.sizecounts.If you are using data stream, you may need to use
GET _data_stream/<data-stream-name>to get the list of the backing indices, and then specify them by usingGET _cat/indices/<backing-index-name>?v=trueto check. When you restore the backing indices of a data stream, some considerations apply, and you might need to manually add the restored indices into your data stream or recreate your data stream.Once your data has completed restoration from searchable snapshots to the target data tier,
DELETEsearchable snapshot indices using the prefix from step 2.DELETE <searchable-snapshot-index-prefix>-<index_name>Delete the searchable snapshots by following these steps:
Open Kibana, go to the Snapshot and Restore management page using the navigation menu or the global search field, and go to the Snapshots tab. (Alternatively, go to
<kibana-endpoint>/app/management/data/snapshot_restore/snapshots.)Search for
*<ilm-policy-name>*Bulk select the snapshots and delete them
In the example we are deleting the snapshots associated with the
policy_with_frozen_phase.
Confirm that no shards remain on the data nodes you wish to remove using
GET _cat/allocation?v=true&s=node.Edit your cluster from the console to disable the data tier.
Once the plan change completes, confirm that there are no remaining nodes associated with the disabled tier and that
GET _cluster/healthreportsgreen. If this is the case, re-enable ILM.POST _ilm/start