Index basics
Elastic Stack Serverless
This content applies to: ![]()
![]()
![]()
An index is a fundamental unit of storage in Elasticsearch. It is a collection of documents uniquely identified by a name or an alias. This unique name is important because it’s used to target the index in search queries and other operations.
A closely related concept is a data stream. This index abstraction is optimized for append-only timestamped data, and is made up of hidden, auto-generated backing indices. If you’re working with timestamped data, we recommend the Elastic Observability solution for additional tools and optimized content.
An index is made up of the following components.
Elasticsearch serializes and stores data in the form of JSON documents. A document is a set of fields, which are key-value pairs that contain your data. Each document has a unique ID, which you can create or have Elasticsearch auto-generate.
A simple Elasticsearch document might look like this:
{
"_index": "my-first-elasticsearch-index",
"_id": "DyFpo5EBxE8fzbb95DOa",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"email": "john@smith.com",
"first_name": "John",
"last_name": "Smith",
"info": {
"bio": "Eco-warrior and defender of the weak",
"age": 25,
"interests": [
"dolphins",
"whales"
]
},
"join_date": "2024/05/01"
}
}
An indexed document contains data and metadata. Metadata fields are system fields that store information about the documents. In Elasticsearch, metadata fields are prefixed with an underscore. For example, the following fields are metadata fields:
_index: The name of the index where the document is stored._id: The document’s ID. IDs must be unique per index.
Each index has a mapping or schema for how the fields in your documents are indexed. A mapping defines the data type for each field, how the field should be indexed, and how it should be stored.
Elastic's index management features are an easy, convenient way to manage your cluster's indices, data streams, index templates, and enrich policies. Practicing good index management ensures your data is stored correctly and in the most cost-effective way possible.
Go to Project settings → Management → Index Management.
Investigate your indices and perform operations from the Indices view.
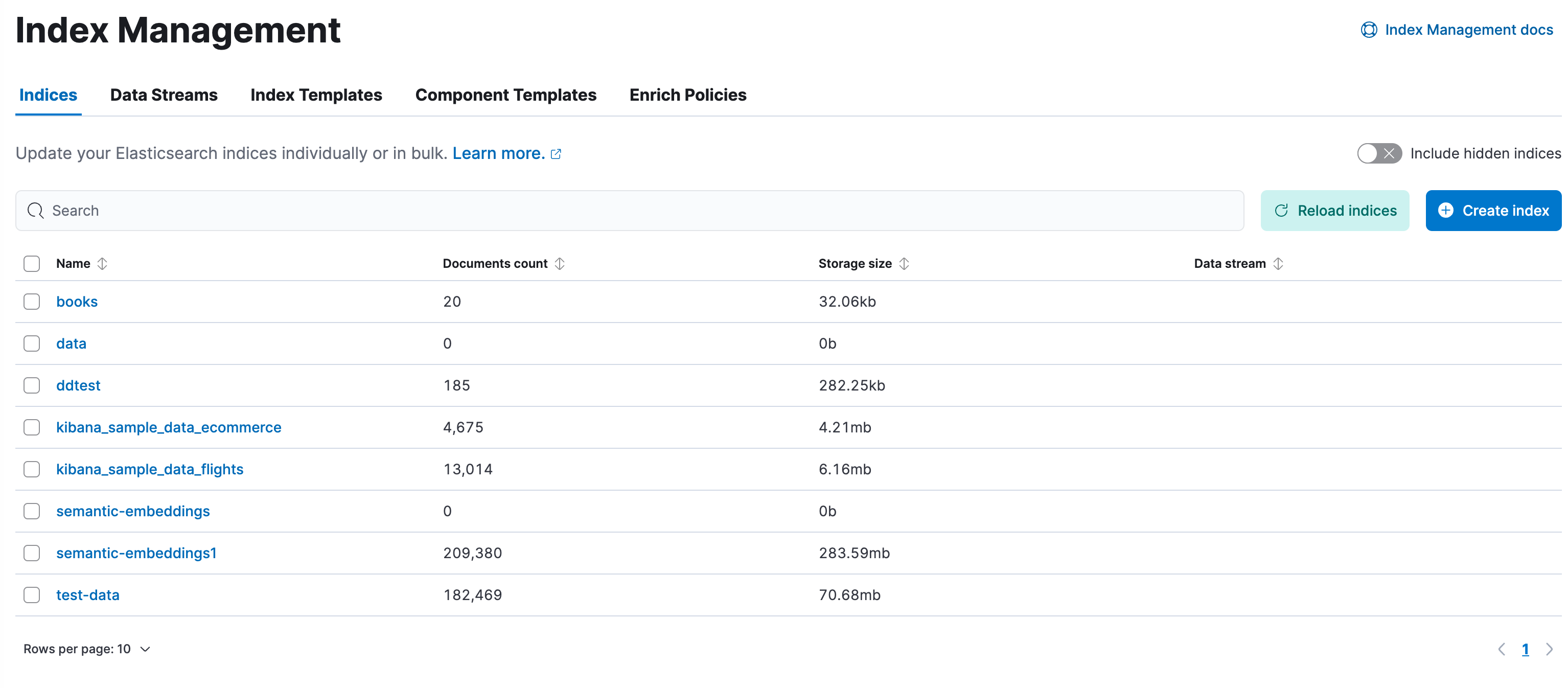
- To show details and perform operations, click the index name. To perform operations on multiple indices, select their checkboxes and then open the Manage menu. For more information on managing indices, refer to Index APIs.
- To filter the list of indices, use the search bar or click a badge. Badges indicate if an index is a follower index, a rollup index, or frozen.
- To drill down into the index mappings, settings, and statistics, click an index name. From this view, you can navigate to Discover to further explore the documents in the index.
- To create new indices, use the Create index wizard.
A data stream lets you store append-only time series data across multiple indices while giving you a single named resource for requests.
Investigate your data streams and address lifecycle management needs in the Data Streams view.
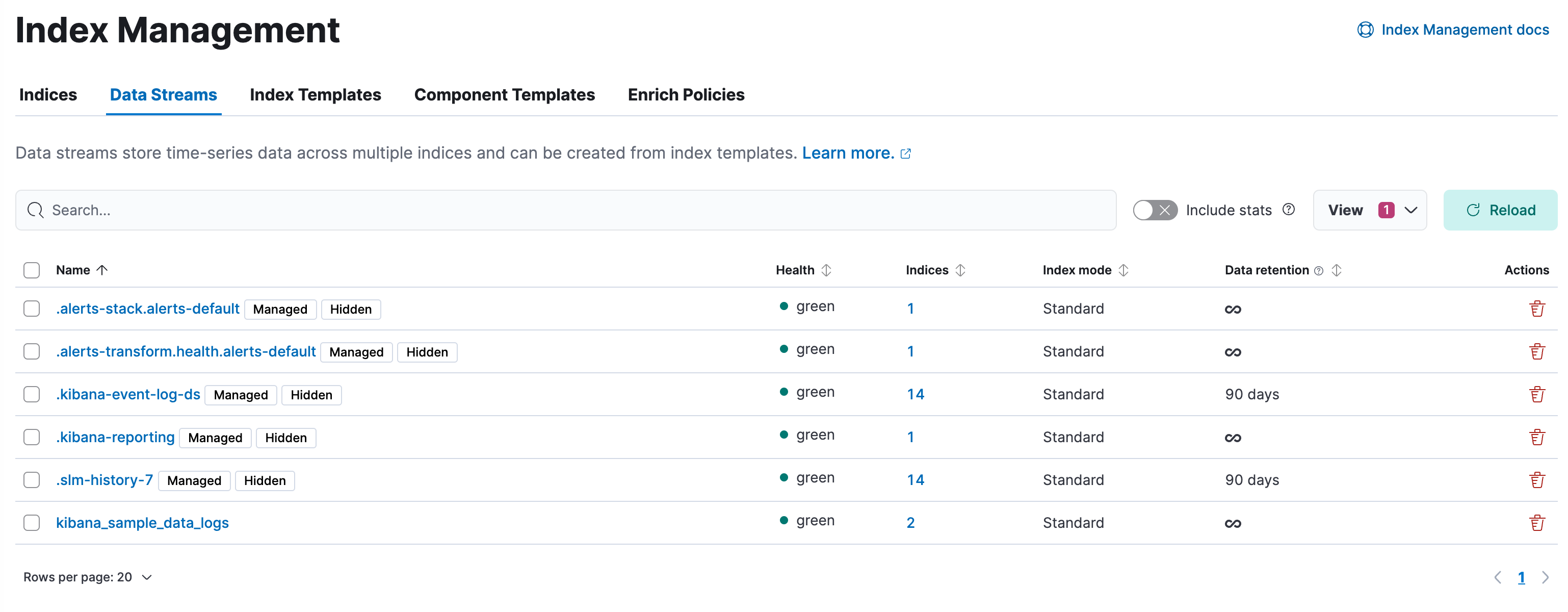
In Elasticsearch Serverless, indices matching the logs-*-* pattern use the logsDB index mode by default. The logsDB index mode creates a logs data stream.
- To view information about the stream's backing indices, click the number in the Indices column.
- A value in the Data retention column indicates that the data stream is managed by a data stream lifecycle policy. This value is the time period for which your data is guaranteed to be stored. Data older than this period can be deleted by Elasticsearch at a later time.
- To modify the data retention value, select an index, open the Manage menu, and click Edit data retention.
- To view more information about a data stream, such as its generation or its current index lifecycle policy, click the stream's name. From this view, you can navigate to Discover to further explore data within the data stream.
An index template is a way to tell Elasticsearch how to configure an index when it is created.
Create, edit, clone, and delete your index templates in the Index Templates view. Changes made to an index template do not affect existing indices.
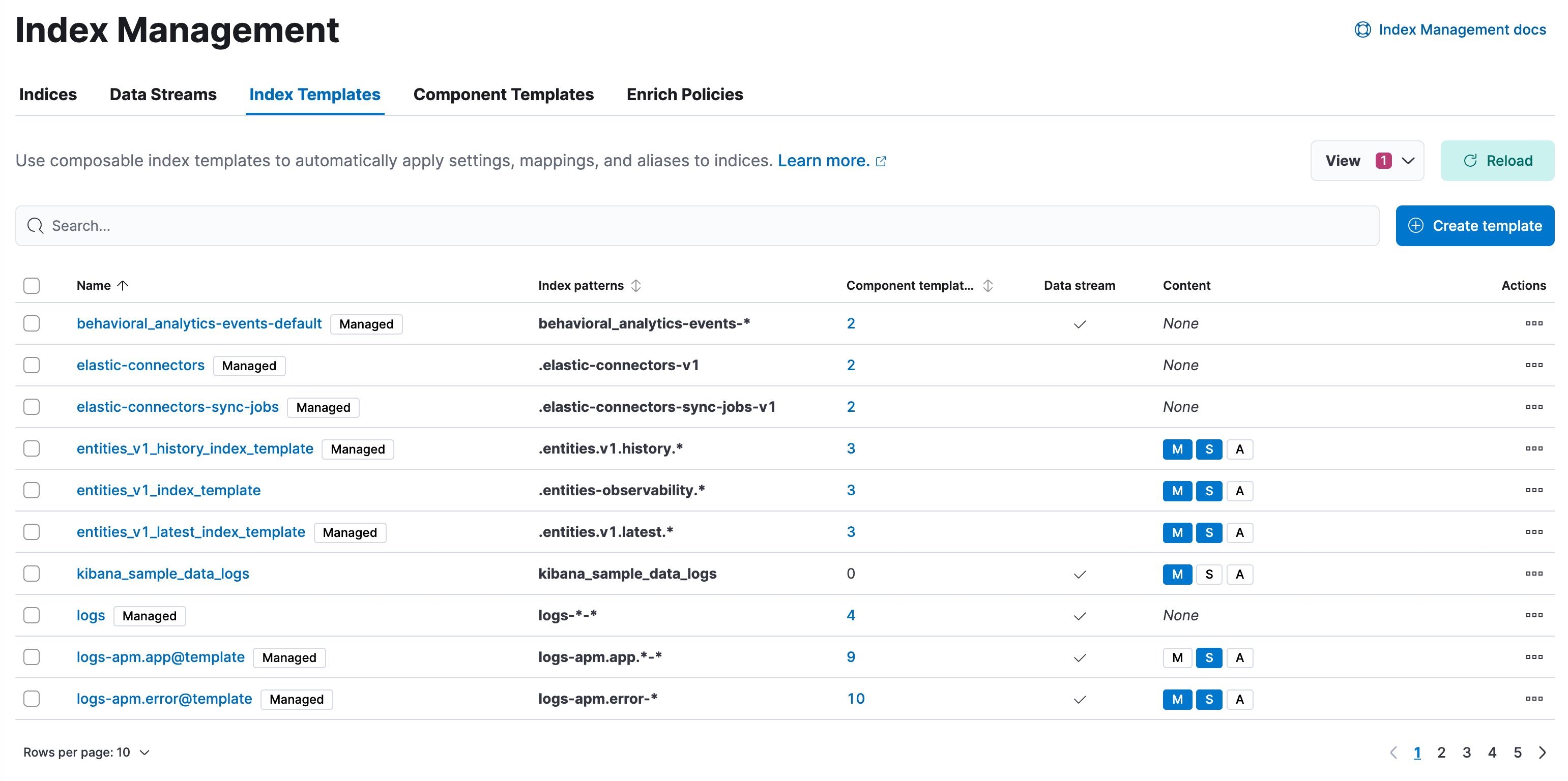
- To show details and perform operations, click the template name.
- To view more information about the component templates within an index template, click the value in the Component templates column.
- Values in the Content column indicate whether a template contains index mappings, settings, and aliases.
- To create new index templates, use the Create template wizard.
Component templates are reusable building blocks that configure mappings, settings, and aliases.
Create, edit, clone, and delete your component templates in the Component Templates view.
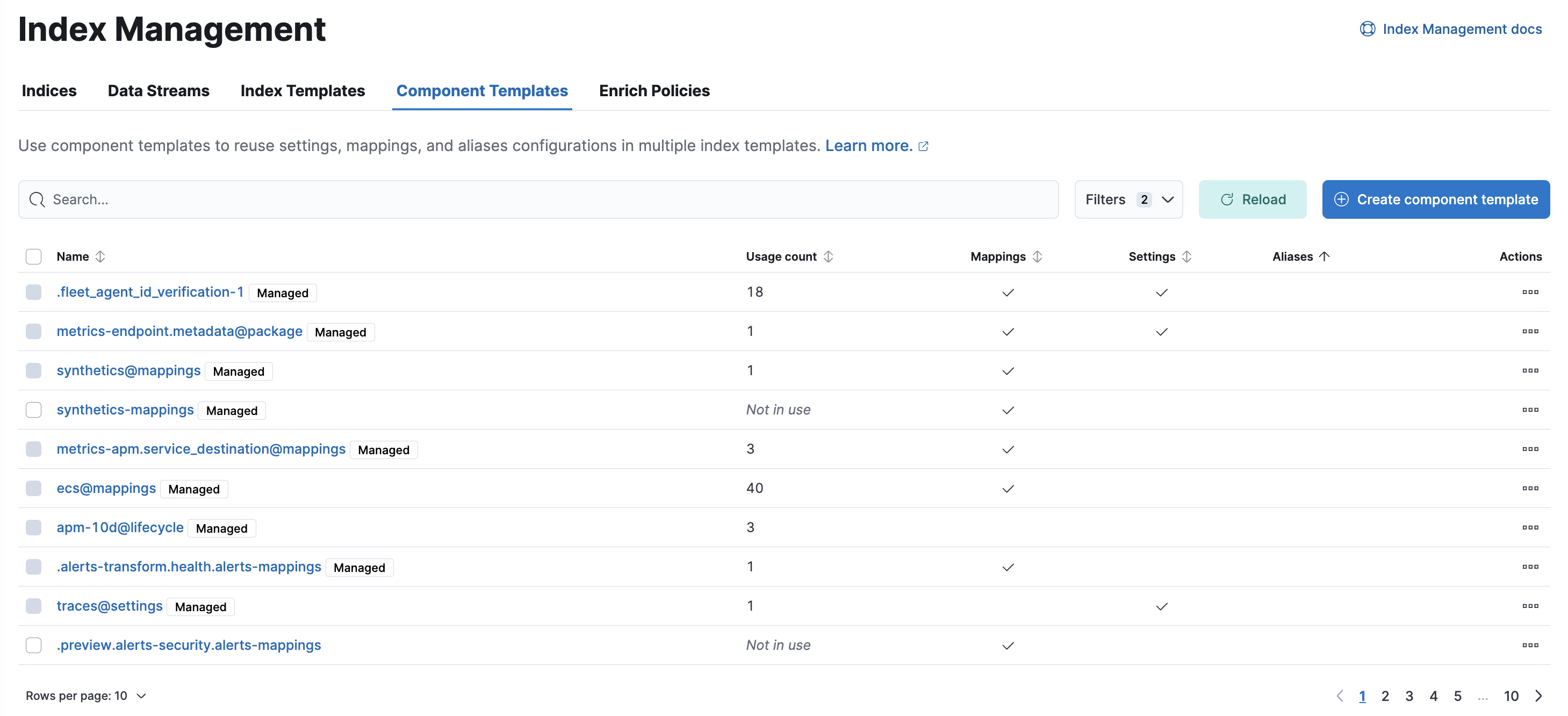
- To show details and perform operations, click the template name.
- To create new component templates, use the Create component template wizard.
An enrich policy is a set of configuration options used to add the right enrich data to the right incoming documents.
Add data from your existing indices to incoming documents using the Enrich Policies view.
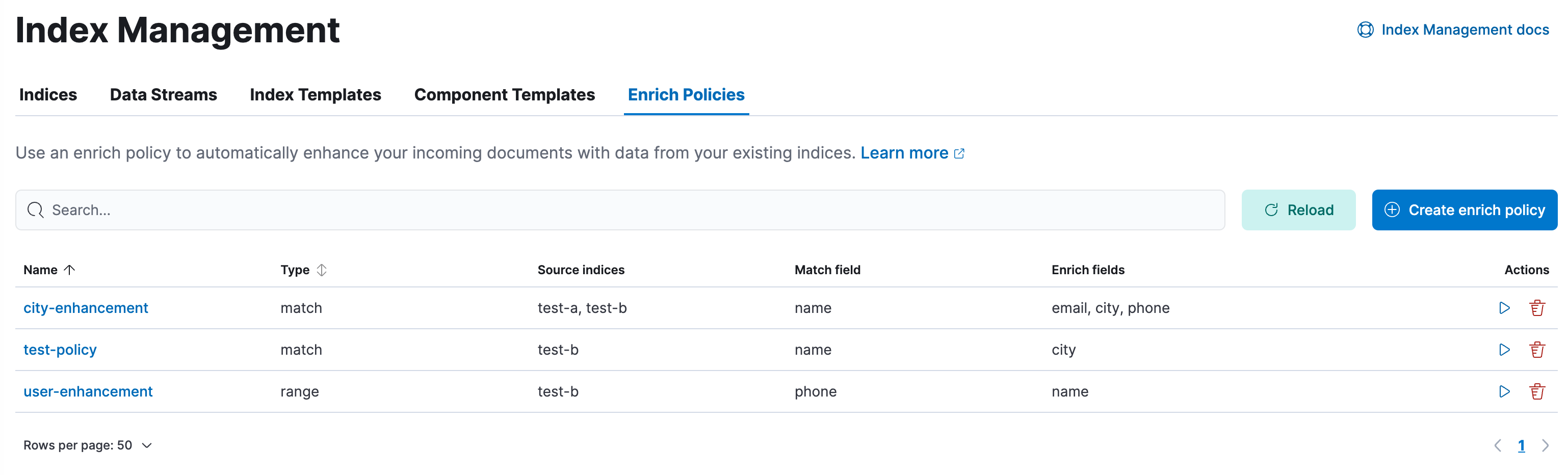
- To show details click the policy name.
- To perform operations, click the policy name or use the buttons in the Actions column.
- To create new policies, use the Create enrich policy wizard.
You must execute a new enrich policy before you can use it with an enrich processor. When executed, an enrich policy uses enrich data from the policy's source indices to create a streamlined system index called the enrich index. The policy uses this index to match and enrich incoming documents.