Integrate with third-party services
Elastic Stack Serverless
Elasticsearch provides a machine learning inference API to create and manage inference endpoints to integrate with machine learning models provide by popular third-party services like Amazon Bedrock, Anthropic, Azure AI Studio, Cohere, Google AI, Mistral, OpenAI, Hugging Face, and more.
Learn how to integrate with specific services in the subpages of this section.
You can also manage inference endpoints using the UI.
The Inference endpoints page provides an interface for managing inference endpoints.
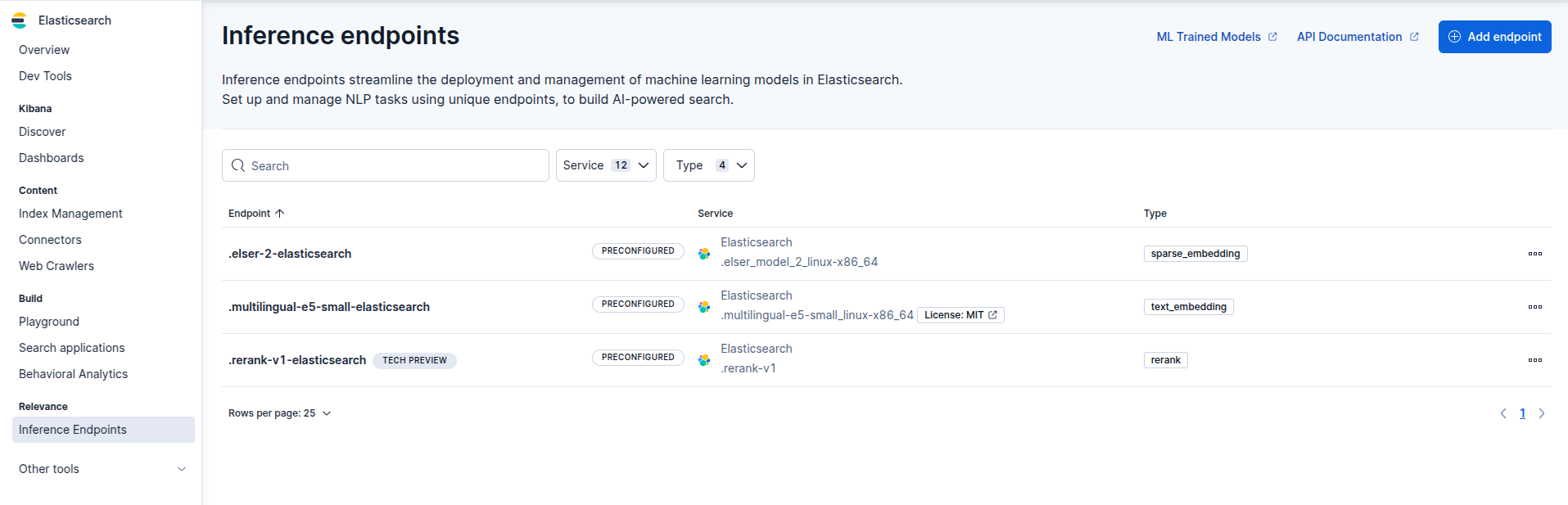
Available actions:
- Add new endpoint
- View endpoint details
- Copy the inference endpoint ID
- Delete endpoints
To add a new interference endpoint using the UI:
- Select the Add endpoint button.
- Select a service from the drop down menu.
- Provide the required configuration details.
- Select Save to create the endpoint.
Adaptive allocations allow inference services to dynamically adjust the number of model allocations based on the current load.
When adaptive allocations are enabled:
- The number of allocations scales up automatically when the load increases.
- Allocations scale down to a minimum of 0 when the load decreases, saving resources.
For more information about adaptive allocations and resources, refer to the trained model autoscaling documentation.
Your Elasticsearch deployment contains preconfigured inference endpoints which makes them easier to use when defining semantic_text fields or using inference processors. The following list contains the default {infer} endpoints listed by inference_id:
.elser-2-elasticsearch: uses the ELSER built-in trained model forsparse_embeddingtasks (recommended for English language tex). Themodel_idis.elser_model_2_linux-x86_64..multilingual-e5-small-elasticsearch: uses the E5 built-in trained model fortext_embeddingtasks (recommended for non-English language texts). Themodel_idis.e5_model_2_linux-x86_64.
Use the inference_id of the endpoint in a semantic_text field definition or when creating an inference processor. The API call will automatically download and deploy the model which might take a couple of minutes. Default inference enpoints have adaptive allocations enabled. For these models, the minimum number of allocations is 0. If there is no inference activity that uses the endpoint, the number of allocations will scale down to 0 automatically after 15 minutes.
Inference endpoints have a limit on the amount of text they can process at once, determined by the model's input capacity. Chunking is the process of splitting the input text into pieces that remain within these limits.
It occurs when ingesting documents into semantic_text fields. Chunking also helps produce sections that are digestible for humans. Returning a long document in search results is less useful than providing the most relevant chunk of text.
Each chunk will include the text subpassage and the corresponding embedding generated from it.
By default, documents are split into sentences and grouped in sections up to 250 words with 1 sentence overlap so that each chunk shares a sentence with the previous chunk. Overlapping ensures continuity and prevents vital contextual information in the input text from being lost by a hard break.
Elasticsearch uses the ICU4J library to detect word and sentence boundaries for chunking. Word boundaries are identified by following a series of rules, not just the presence of a whitespace character. For written languages that do use whitespace such as Chinese or Japanese dictionary lookups are used to detect word boundaries.
Two strategies are available for chunking: sentence and word.
The sentence strategy splits the input text at sentence boundaries. Each chunk contains one or more complete sentences ensuring that the integrity of sentence-level context is preserved, except when a sentence causes a chunk to exceed a word count of max_chunk_size, in which case it will be split across chunks. The sentence_overlap option defines the number of sentences from the previous chunk to include in the current chunk which is either 0 or 1.
The word strategy splits the input text on individual words up to the max_chunk_size limit. The overlap option is the number of words from the previous chunk to include in the current chunk.
The default chunking strategy is sentence.
The following example creates an inference endpoint with the elasticsearch service that deploys the ELSER model by default and configures the chunking behavior.
PUT _inference/sparse_embedding/small_chunk_size {
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1
},
"chunking_settings": {
"strategy": "sentence",
"max_chunk_size": 100,
"sentence_overlap": 0
}
}