Autoscaling in Elastic Cloud Enterprise and Elastic Cloud Hosted
ECE Elastic Cloud Hosted
When you first create a deployment it can be challenging to determine the amount of storage your data nodes will require. The same is relevant for the amount of memory and CPU that you want to allocate to your machine learning nodes. It can become even more challenging to predict these requirements for weeks or months into the future. In an ideal scenario, these resources should be sized to both ensure efficient performance and resiliency, and to avoid excess costs. Autoscaling can help with this balance by adjusting the resources available to a deployment automatically as loads change over time, reducing the need for monitoring and manual intervention.
To learn more about configuring and managing autoscaling, check the following sections:
- Overview
- When does autoscaling occur?
- Notifications
- Restrictions and limitations
- Enable or disable autoscaling
- Update your autoscaling settings
You can also have a look at our autoscaling example, as well as a sample request to create an autoscaled deployment through the API.
Autoscaling is enabled for the Machine Learning tier by default for new deployments.
Currently, autoscaling behavior is as follows:
Data tiers
- Each Elasticsearch data tier scales upward based on the amount of available storage. When we detect more storage is needed, autoscaling will scale up each data tier independently to ensure you can continue and ingest more data to your hot and content tier, or move data to the warm, cold, or frozen data tiers.
- In addition to scaling up existing data tiers, a new data tier will be automatically added when necessary, based on your index lifecycle management policies.
- To control the maximum size of each data tier and ensure it will not scale above a certain size, you can use the maximum size per zone field.
- Autoscaling based on memory or CPU, as well as autoscaling downward, is not currently supported. In case you want to adjust the size of your data tier to add more memory or CPU, or in case you deleted data and want to scale it down, you can set the current size per zone of each data tier manually.
Machine learning nodes
- Machine learning nodes can scale upward and downward based on the configured machine learning jobs.
- When a machine learning job is opened, or a machine learning trained model is deployed, if there are no machine learning nodes in your deployment, the autoscaling mechanism will automatically add machine learning nodes. Similarly, after a period of no active machine learning jobs, any enabled machine learning nodes are disabled automatically.
- To control the maximum size of your machine learning nodes and ensure they will not scale above a certain size, you can use the maximum size per zone field.
- To control the minimum size of your machine learning nodes and ensure the autoscaling mechanism will not scale machine learning below a certain size, you can use the minimum size per zone field.
- The determination of when to scale is based on the expected memory and CPU requirements for the currently configured machine learning jobs and trained models.
For any Elasticsearch component the number of availability zones is not affected by autoscaling. You can always set the number of availability zones manually and the autoscaling mechanism will add or remove capacity per availability zone.
Several factors determine when data tiers or machine learning nodes are scaled.
For a data tier, an autoscaling event can be triggered in the following cases:
Based on an assessment of how shards are currently allocated, and the amount of storage and buffer space currently available.
When past behavior on a hot tier indicates that the influx of data can increase significantly in the near future. Refer to Reactive storage decider and Proactive storage decider for more detail.
Through ILM policies. For example, if a deployment has only hot nodes and autoscaling is enabled, it automatically creates warm or cold nodes, if an ILM policy is trying to move data from hot to warm or cold nodes.
On machine learning nodes, scaling is determined by an estimate of the memory and CPU requirements for the currently configured jobs and trained models. When a new machine learning job tries to start, it looks for a node with adequate native memory and CPU capacity. If one cannot be found, it stays in an opening state. If this waiting job exceeds the queueing limit set in the machine learning decider, a scale up is requested. Conversely, as machine learning jobs run, their memory and CPU usage might decrease or other running jobs might finish or close. In this case, if the duration of decreased resource usage exceeds the set value for down_scale_delay, a scale down is requested. Check Machine learning deciderfor more detail. To learn more about machine learning jobs in general, check Create anomaly detection jobs
On a highly available deployment, autoscaling events are always applied to instances in each availability zone simultaneously, to ensure consistency.
In the event that a data tier or machine learning node scales up to its maximum possible size, you’ll receive an email, and a notice also appears on the deployment overview page prompting you to adjust your autoscaling settings to ensure optimal performance.
In Elastic Cloud Enterprise deployments, a warning is also issued in the ECE service-constructor logs with the field labels.autoscaling_notification_type and a value of data-tier-at-limit (for a fully scaled data tier) or ml-tier-at-limit (for a fully scaled machine learning node). The warning is indexed in the logging-and-metrics deployment, so you can use that event to configure an email notification.
The following are known limitations and restrictions with autoscaling:
- Autoscaling will not run if the cluster is unhealthy or if the last Elasticsearch plan failed.
In Elastic Cloud Hosted the following additional limitations apply:
- Trial deployments cannot be configured to autoscale beyond the normal Trial deployment size limits. The maximum size per zone is increased automatically from the Trial limit when you convert to a paid subscription.
- ELSER deployments do not scale automatically. For more information, refer to ELSER and Trained model autoscaling.
In Elastic Cloud Enterprise, the following additional limitations apply:
- In the event that an override is set for the instance size or disk quota multiplier for an instance by means of the Instance Overrides API, autoscaling will be effectively disabled. It’s recommended to avoid adjusting the instance size or disk quota multiplier for an instance that uses autoscaling, since the setting prevents autoscaling.
To enable or disable autoscaling on a deployment:
Log in to the ECE Cloud UI or Elastic Cloud Console.
On the Deployments page, select your deployment.
Narrow your deployments by name, ID, or choose from several other filters. To customize your view, use a combination of filters, or change the format from a grid to a list.
In your deployment menu, select Edit.
Select desired autoscaling configuration for this deployment using Enable Autoscaling for: dropdown menu.
Select Confirm to have the autoscaling change and any other settings take effect. All plan changes are shown on the Deployment Activity page.
When autoscaling has been enabled, the autoscaled nodes resize according to the autoscaling settings. Current sizes are shown on the deployment overview page.
When autoscaling has been disabled, you need to adjust the size of data tiers and machine learning nodes manually.
Each autoscaling setting is configured with a default value. You can adjust these if necessary, as follows:
Log in to the ECE Cloud UI or Elastic Cloud Console.
On the Deployments page, select your deployment.
Narrow your deployments by name, ID, or choose from several other filters. To customize your view, use a combination of filters, or change the format from a grid to a list.
In your deployment menu, select Edit.
To update a data tier:
- Use the dropdown box to set the Maximum size per zone to the largest amount of resources that should be allocated to the data tier automatically. The resources will not scale above this value.
- You can also update the Current size per zone. If you update this setting to match the Maximum size per zone, the data tier will remain fixed at that size.
- For a hot data tier you can also adjust the Forecast window. This is the duration of time, up to the present, for which past storage usage is assessed in order to predict when additional storage is needed.
- Select Save to apply the changes to your deployment.
To update machine learning nodes:
- Use the dropdown box to set the Minimum size per zone and Maximum size per zone to the smallest and largest amount of resources, respectively, that should be allocated to the nodes automatically. The resources allocated to machine learning will not exceed these values. If you set these two settings to the same value, the machine learning node will remain fixed at that size.
- Select Save to apply the changes to your deployment.
On Elastic Cloud Enterprise, system-owned deployment templates include the default values for all deployment autoscaling settings.
To help you better understand the available autoscaling settings, this example describes a typical autoscaling workflow on sample Elastic Cloud Enterprise or Elastic Cloud Hosted deployment.
Enable autoscaling:
On an existing deployment, open the deployment Edit page to find the option to turn on autoscaling.
When you create a new deployment, you can find the autoscaling option under Advanced settings.
Once you confirm your changes or create a new deployment, autoscaling is activated with system default settings that you can adjust as needed (though for most use cases the default settings will likely suffice).
View and adjust autoscaling settings on data tiers:
Open the Edit page for your deployment to get the current and maximum size per zone of each Elasticsearch data tier. In this example, the hot data and content tier has the following settings:
Current size per zone Maximum size per zone 45GB storage 1.41TB storage 1GB RAM 32GB RAM Up to 2.5 vCPU 5 vCPU The fault tolerance for the data tier is set to 2 availability zones.
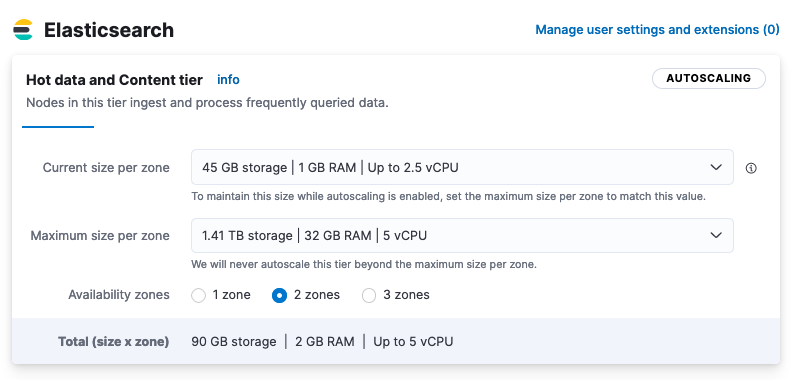
Use the dropdown boxes to adjust the current and/or the maximum size of the data tier. Capacity will be added to the hot content and data tier when required, based on its past and present storage usage, until it reaches the maximum size per zone. Any scaling events are applied simultaneously across availability zones. In this example, the tier has plenty of room to scale relative to its current size, and it will not scale above the maximum size setting. There is no minimum size setting since downward scaling is currently not supported on data tiers.
View and adjust autoscaling settings on a machine learning instance:
From the deployment Edit page you can check the minimum and maximum size of your deployment’s machine learning instances. In this example, the machine learning instance has the following settings:
Minimum size per zone Maximum size per zone 1GB RAM 64GB RAM 0.5 vCPU up to 8 vCPU 32 vCPU The fault tolerance for the machine learning instance is set to 1 availability zone.

Use the dropdown boxes to adjust the minimum and/or the maximum size of the data tier. Capacity will be added to or removed from the machine learning instances as needed. The need for a scaling event is determined by the expected memory and vCPU requirements for the currently configured machine learning job. Any scaling events are applied simultaneously across availability zones. Note that unlike data tiers, machine learning nodes do not have a Current size per zone setting. That setting is not needed since machine learning nodes support both upward and downward scaling.
Over time, the volume of data and the size of any machine learning jobs in your deployment are likely to grow. Let’s assume that to meet storage requirements your hot data tier has scaled up to its maximum allowed size of 64GB RAM and 32 vCPU. At this point, a notification appears on the deployment overview page indicating that the tier has scaled to capacity.
If you expect a continued increase in either storage, memory, or vCPU requirements, you can use the Maximum size per zone dropdown box to adjust the maximum capacity settings for your data tiers and machine learning instances, as appropriate. And, you can always re-adjust these levels downward if the requirements change.
As you can see, autoscaling greatly reduces the manual work involved to manage a deployment. The deployment capacity adjusts automatically as demands change, within the boundaries that you define. Check our main Deployment autoscaling page for more information.
This example demonstrates how to use the Elastic Cloud RESTful API to create a deployment with autoscaling enabled.
The example deployment has a hot data and content tier, warm data tier, cold data tier, and a machine learning node, all of which will scale within the defined parameters. To learn about the autoscaling settings, check Deployment autoscaling and Autoscaling example.
To learn more about the Elastic Cloud Enterprise API, see the RESTful API documentation. For details on the Elastic Cloud Hosted API, check RESTful API.
Note the following requirements when you run this API request:
All Elasticsearch components must be included in the request, even if they are not enabled (that is, if they have a zero size). All components are included in this example.
The request requires a format that supports data tiers. Specifically, all Elasticsearch components must contain the following properties:
idnode_attributesnode_roles
The
size,autoscaling_min, andautoscaling_maxproperties must be specified according to the following rules. This is because:- On data tiers only upward scaling is currently supported.
- On machine learning nodes both upward and downward scaling is supported.
- On all other components autoscaling is not currently supported.
On Elastic Cloud Enterprise, autoscaling is supported for custom deployment templates on version 2.12 and above. To learn more, refer to Updating custom templates to support
node_rolesand autoscaling.
size |
autoscaling_min |
autoscaling_max |
|
| data tier | ✓ | ✕ | ✓ |
| machine learning node | ✕ | ✓ | ✓ |
| coordinating and master nodes | ✓ | ✕ | ✕ |
| Kibana | ✓ | ✕ | ✕ |
| APM | ✓ | ✕ | ✕ |
✓ = Include the property.
✕ = Do not include the property.
These rules match the behavior of the Elastic Cloud Hosted and Elastic Cloud Enterprise user console.
The
elasticsearchobject must contain the property"autoscaling_enabled": true.
Although autoscaling can scale some tiers by CPU, the primary measurement of tier size is memory. Limits on tier size are in terms of memory.
Run this example API request to create a deployment with autoscaling:
curl -k -X POST -H "Authorization: ApiKey $ECE_API_KEY" https://$COORDINATOR_HOST:12443/api/v1/deployments -H 'content-type: application/json' -d '
{
"name": "my-first-autoscaling-deployment",
"resources": {
"elasticsearch": [
{
"ref_id": "main-elasticsearch",
"region": "ece-region",
"plan": {
"autoscaling_enabled": true,
"cluster_topology": [
{
"id": "hot_content",
"node_roles": [
"master",
"ingest",
"remote_cluster_client",
"data_hot",
"transform",
"data_content"
],
"zone_count": 1,
"elasticsearch": {
"node_attributes": {
"data": "hot"
},
"enabled_built_in_plugins": []
},
"instance_configuration_id": "data.default",
"size": {
"value": 4096,
"resource": "memory"
},
"autoscaling_max": {
"value": 2097152,
"resource": "memory"
}
},
{
"id": "warm",
"node_roles": [
"data_warm",
"remote_cluster_client"
],
"zone_count": 1,
"elasticsearch": {
"node_attributes": {
"data": "warm"
},
"enabled_built_in_plugins": []
},
"instance_configuration_id": "data.highstorage",
"size": {
"value": 0,
"resource": "memory"
},
"autoscaling_max": {
"value": 2097152,
"resource": "memory"
}
},
{
"id": "cold",
"node_roles": [
"data_cold",
"remote_cluster_client"
],
"zone_count": 1,
"elasticsearch": {
"node_attributes": {
"data": "cold"
},
"enabled_built_in_plugins": []
},
"instance_configuration_id": "data.highstorage",
"size": {
"value": 0,
"resource": "memory"
},
"autoscaling_max": {
"value": 2097152,
"resource": "memory"
}
},
{
"id": "coordinating",
"node_roles": [
"ingest",
"remote_cluster_client"
],
"zone_count": 1,
"instance_configuration_id": "coordinating",
"size": {
"value": 0,
"resource": "memory"
},
"elasticsearch": {
"enabled_built_in_plugins": []
}
},
{
"id": "master",
"node_roles": [
"master"
],
"zone_count": 1,
"instance_configuration_id": "master",
"size": {
"value": 0,
"resource": "memory"
},
"elasticsearch": {
"enabled_built_in_plugins": []
}
},
{
"id": "ml",
"node_roles": [
"ml",
"remote_cluster_client"
],
"zone_count": 1,
"instance_configuration_id": "ml",
"autoscaling_min": {
"value": 0,
"resource": "memory"
},
"autoscaling_max": {
"value": 2097152,
"resource": "memory"
},
"elasticsearch": {
"enabled_built_in_plugins": []
}
}
],
"elasticsearch": {
"version": "8.13.1"
},
"deployment_template": {
"id": "default"
}
},
"settings": {
"dedicated_masters_threshold": 6
}
}
],
"kibana": [
{
"ref_id": "main-kibana",
"elasticsearch_cluster_ref_id": "main-elasticsearch",
"region": "ece-region",
"plan": {
"zone_count": 1,
"cluster_topology": [
{
"instance_configuration_id": "kibana",
"size": {
"value": 1024,
"resource": "memory"
},
"zone_count": 1
}
],
"kibana": {
"version": "8.13.1"
}
}
}
],
"apm": [
{
"ref_id": "main-apm",
"elasticsearch_cluster_ref_id": "main-elasticsearch",
"region": "ece-region",
"plan": {
"cluster_topology": [
{
"instance_configuration_id": "apm",
"size": {
"value": 512,
"resource": "memory"
},
"zone_count": 1
}
],
"apm": {
"version": "8.13.1"
}
}
}
],
"enterprise_search": []
}
}
'
curl -XPOST \
-H 'Content-Type: application/json' \
-H "Authorization: ApiKey $EC_API_KEY" \
"https://api.elastic-cloud.com/api/v1/deployments" \
-d '
{
"name": "my-first-autoscaling-deployment",
"resources": {
"elasticsearch": [
{
"ref_id": "main-elasticsearch",
"region": "us-east-1",
"plan": {
"autoscaling_enabled": true,
"cluster_topology": [
{
"id": "hot_content",
"node_roles": [
"remote_cluster_client",
"data_hot",
"transform",
"data_content",
"master",
"ingest"
],
"zone_count": 2,
"elasticsearch": {
"node_attributes": {
"data": "hot"
},
"enabled_built_in_plugins": []
},
"instance_configuration_id": "aws.data.highio.i3",
"size": {
"resource": "memory",
"value": 8192
},
"autoscaling_max": {
"value": 118784,
"resource": "memory"
}
},
{
"id": "warm",
"node_roles": [
"data_warm",
"remote_cluster_client"
],
"zone_count": 2,
"elasticsearch": {
"node_attributes": {
"data": "warm"
},
"enabled_built_in_plugins": []
},
"instance_configuration_id": "aws.data.highstorage.d3",
"size": {
"value": 0,
"resource": "memory"
},
"autoscaling_max": {
"value": 118784,
"resource": "memory"
}
},
{
"id": "cold",
"node_roles": [
"data_cold",
"remote_cluster_client"
],
"zone_count": 1,
"elasticsearch": {
"node_attributes": {
"data": "cold"
},
"enabled_built_in_plugins": []
},
"instance_configuration_id": "aws.data.highstorage.d3",
"size": {
"value": 0,
"resource": "memory"
},
"autoscaling_max": {
"value": 59392,
"resource": "memory"
}
},
{
"id": "coordinating",
"zone_count": 2,
"node_roles": [
"ingest",
"remote_cluster_client"
],
"instance_configuration_id": "aws.coordinating.m5d",
"size": {
"value": 0,
"resource": "memory"
},
"elasticsearch": {
"enabled_built_in_plugins": []
}
},
{
"id": "master",
"node_roles": [
"master"
],
"zone_count": 3,
"instance_configuration_id": "aws.master.r5d",
"size": {
"value": 0,
"resource": "memory"
},
"elasticsearch": {
"enabled_built_in_plugins": []
}
},
{
"id": "ml",
"node_roles": [
"ml",
"remote_cluster_client"
],
"zone_count": 1,
"instance_configuration_id": "aws.ml.m5d",
"autoscaling_min": {
"value": 0,
"resource": "memory"
},
"autoscaling_max": {
"value": 61440,
"resource": "memory"
},
"elasticsearch": {
"enabled_built_in_plugins": []
}
}
],
"elasticsearch": {
"version": "7.11.0"
},
"deployment_template": {
"id": "aws-io-optimized-v2"
}
},
"settings": {
"dedicated_masters_threshold": 6
}
}
],
"kibana": [
{
"elasticsearch_cluster_ref_id": "main-elasticsearch",
"region": "us-east-1",
"plan": {
"cluster_topology": [
{
"instance_configuration_id": "aws.kibana.r5d",
"zone_count": 1,
"size": {
"resource": "memory",
"value": 1024
}
}
],
"kibana": {
"version": "7.11.0"
}
},
"ref_id": "main-kibana"
}
],
"apm": [
{
"elasticsearch_cluster_ref_id": "main-elasticsearch",
"region": "us-east-1",
"plan": {
"cluster_topology": [
{
"instance_configuration_id": "aws.apm.r5d",
"zone_count": 1,
"size": {
"resource": "memory",
"value": 512
}
}
],
"apm": {
"version": "7.11.0"
}
},
"ref_id": "main-apm"
}
],
"enterprise_search": []
}
}
'